每個人使用文字都有自己的習慣,習慣強烈的,我們能夠單憑人力就可辨別一份文件或一封Email到底是誰寫的,盡管這份文件或Email並沒有留下任何署名;然而,有些人的用字習慣可能是隱晦的,因而依靠人力很難去辨別原作者,此時就需要去建構Machine Learning的分析模型來解決問題
Text Learning是利用機器學習,依據郵件中使用的文字種類,頻率多寡,自動判斷郵件的寄件人
Enron Dataset 包含許多email文件,從中選取寄信者來自Crist和Sara的郵件,對一部份來自Chris和Sara的郵件作Machine Learning,試圖建構一個模型,在不知道寄件者的情況下,想要僅憑郵件的內容,便可判別此郵件到底是來自Crist還是Sara
- 此程式可分為兩個部份, Preprocess和SVM
- Preprocess:對Email進行處理,擷取內容,並以TFIDF計算文字(Word Feature)在每一封郵件的重要性
- SVM:利用Support Vector Machine演算法,藉由處理過的文字(Word Feature),建立分辨寄件者的模型
程式碼在GitHub頁面,請點這裡
下載GitHub上的Repository:
$ git clone https://github.com/linhung0319/text-learning.git
於svm資料夾內執行主程式 svm_author_id.py
Preprocess
1.Parse Out Email Text
1.讀取email文件,並從中擷取出email的內容
2.去除掉email內容中的標點符號和空格
3.對email的內容,取出每個英文字的Stem
引入所需的Library
from nltk.stem.snowball import SnowballStemmer
import string
從檔案f讀取email文件
### go back to the beginning of the file and read all the text
def parseOutText(f):
f.seek(0)
all_text = f.read()
以下讀取一個email的範例:
To: Katie_and_Sebastians_Excellent_Students@udacity.com
From: katie@udacity.com
X-FileName:
Hi Everyone! If you can read this message, you're properly using parseOutText. Please proceed to the next part of the project!
擷取出email文件中的內容
從email文件範例中可以發現,email的內容存在於 X-FileName: 之後,因此以 X-FileName: 作分割, content[1] 即為email的內容
### split off metadata
content = all_text.split("X-FileName:")
擷取出的email內容, content[1] :
Hi Everyone! If you can read this message, you're properly using parseOutText. Please proceed to the next part of the project!
去除掉email內容中的標點符號,換行符,Tab鍵
### remove punctuation
text_string = content[1].translate(str.maketrans("", "", string.punctuation))
### replace \n, \t, \r with white space
for i in ['\n', '\t', '\r']:
text_string = text_string.replace(i, " ")
處理過後的email內容:
Hi Everyone If you can read this message youre properly using parseOutText Please proceed to the next part of the project
對每個英文字進行Stem轉換
例如英文字中的response, responsive, responsibility, responsible,經過Stem轉換後皆為 respons ,在統計文件中文字個數時,這些具有相同Stem的英文字皆被算成同一種字
### split the text string into individual words, stem each word,
### and append the stemmed word to words (make sure there's a single
### space between each stemmed word)
stemmer = SnowballStemmer('english')
text_list = text_string.strip().split(' ')
words = ''
for word in text_list:
if len(word):
words = words + stemmer.stem(word) + ' '
經過Stem轉換後的email內容:
hi everyon if you can read this messag your proper use parseouttext pleas proceed to the next part of the project
2.Pickle Email Text
1.讀取紀錄Sara和Chris的Email文件路徑
2.經由ParseOutText函式將Email的內容去除掉標點符號和進行Stem轉換
3.使用Pickle儲存經過處理後的Email內容
引入所需的Library
函式parseOutText的內容,請見於上一章 Parse Out Email Text 的解釋
import os
import pickle
from parse_out_email_text import parseOutText
讀取紀錄Sara和Chris的Email文件路徑
./maildir資料夾下儲存了Enron DataSet,其內存在海量的Email文件,因此需要從中找尋出只屬於Sara和Chris的Email文件
from_sara.txt , from_chris.txt 紀錄了在Enron Dataset當種只屬於Sara和Chris的Email文件路徑,例如:
###擷取自from_sara.txt
maildir/bailey-s/deleted_items/101.
maildir/bailey-s/deleted_items/106.
maildir/bailey-s/deleted_items/132.
maildir/bailey-s/deleted_items/185.
.
.
.
因為 pickle_email_text.py 存在於 ./preprocess 資料夾當中,所以需要在Sara和Chris的Email文件路徑的前面加上../,並將其儲存於path當中
from_sara = open('from_sara.txt', 'r')
from_chris = open('from_chris.txt', 'r')
for name, from_person in [("sara", from_sara), ("chris", from_chris)]:
for path in from_person:
path = os.path.join('..', path[:-1])
email = open(path, 'r')
其結果為:
###擷取自from_sara.txt路徑被轉換後的結果
../maildir/bailey-s/deleted_items/101.
../maildir/bailey-s/deleted_items/106.
../maildir/bailey-s/deleted_items/132.
../maildir/bailey-s/deleted_items/185.
.
.
.
經由ParseOutText函式將Email的內容去除掉標點符號和進行Stem轉換
text_string = parseOutText(email)
使用Pickle儲存經過處理後的Email內容
將Email內容以list的方式儲存於 word_data ,list當中的每一個Index對應一封Email
同時將Email的作者以list的方式儲存於 email_authors ,屬於Sara的Email計為0,屬於Chris則計為1
### append the text to word_data
word_data.append(text_string)
### append a 0 to from_data if email is from Sara, and 1 if email is from Chris
if name == "sara":
email_authors.append(0)
else:
email_authors.append(1)
使用Pickle儲存 word_data 和 email_authors
pickle.dump(word_data, open('word_data.pkl', 'wb'))
pickle.dump(email_authors, open('email_authors.pkl', 'wb'))
3.Email Preprocess
1.將Email分為Training Dataset和Testing Dataset
2.對Email的字詞進行TFIDF轉換
3.將字詞(Word Feature)依照其重要性進行篩選,以減少分析模型的Feature數量
引入所需的Library
import pickle
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_selection import SelectPercentile, f_classif
將Email分為Training Dataset和Testing Dataset
分析模型需要有一組Training Dataset,包括文本的內容和其對應的正確作者以建立模型。Testing Dataset則是用來測試建立的模型的準確度
設定原始資料的10%為Training Dataset,90%為Testing Dataset
### test_size is the percentage of events assigned to the test set
### (remainder go into training)
features_train, features_test, labels_train, labels_test = train_test_split(word_data, authors, test_size=0.9, random_state=0)
對字詞進行TFIDF轉換
TF(Term Frequency): 字詞在文件中出現的次數, 理論上同一個字詞在文件中出現的次數越多,表示越重要
IDF(Inverse Document Frequency): log(總文件數 / 某個字詞出現的文件數), 若一個字詞在大部分文件都有出現,表現此字詞普遍存在,並不屬於特定某個文件,因此較不重要
TFIDF即是將 TF 乘以 IDF
### text vectorization--go from strings to lists of numbers
vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5, stop_words='english')
features_train_transformed = vectorizer.fit_transform(features_train)
features_test_transformed = vectorizer.transform(features_test)
sublinear: TF = 1 + log(TF)
max_df=0.5: 若某個字詞出現在文件的個數佔總文件50%以上,則不使用此字詞
stop_words: [a, I, you, me, my, the,…],在英文中很常用但不具備意義或太過普遍出現,不具備被辨識能力的詞彙
將字詞(Word Feature)根據重要性進行篩選
利用F-Test,決定字詞(Word Feature)的重要程度,由於字詞的種類過多,會影響到分析模型的執行速度,因此只取其中10%最重要的字詞當作分析模型分析的依據
### feature selection, because text is super high dimensional and can be really computationally chewy as a result
selector = SelectPercentile(f_classif, percentile=10)
selector.fit(features_train_transformed, labels_train)
features_train_transformed = selector.transform(features_train_transformed).toarray()
features_test_transformed = selector.transform(features_test_transformed).toarray()
f_classif: 以F-Test來計算字詞(Word Feature)的重要性
percentile=10: 只留下10%最重要的字詞,其餘皆被剔除
結論
1.總共有17578封Email,其中1757封作為Traning Dataset,15821封作為Testing Dataset
2.屬於Sara和Chris的Email其數量在Training, Testing Dataset中雖然不相等,但數量極為接近
3.作為分析模型判斷依據的Word Feature總共有1708個
4.Find Signature(補充)
有些Sara和Chris的Email,在結尾會有他們的署名 Sara Shackleton, Chris Germany ,若將這些字詞放入分析模型當中,會使分析發生嚴重的錯誤
例如, Sara Shackleton 這兩個字,可能大量存在於來自Sara的Email當中,這就導致分析模型會將這兩個字當作判別為Sara郵件的重要依據,只要出現Sara或Shackleton字詞的郵件便會被判別為來自Sara。 然而,若是Chris在他的Email當中恰巧提到Sara,這可能導致分析模型因此將Chris的郵件誤判為Sara的郵件,降低分析模型的判別成功率,所以在進行分析前,需要把 Sara Shackleton 和 Chris Germany 從字詞中去掉
除了上述的四個字以外,可能還存在類似署名的字詞存在於郵件當中,需要將其找出
Decision Tree 分析模型若是Feature數量(字詞種類數量)遠大於Training Dataset數量(當作訓練資料的Email文件數量),則會有Overfitting發生,分析模型過於符合Training Dataset,使得分析模型在Testing Dataset上的表現不佳
然而,若是在Email內存在類似署名的字詞,則就算發生了Overfitting,但分析模型在Testing Dataset上仍會有很好的表現
所以為了找出是否仍有類似署名的字詞存在於Email當中,故意讓 Decision Tree Overfitting,再檢查其在Testing Dataset上的表現。若表現極為良好,則表示仍存在署名,需要找出此時對分析模型最具有判別能力的字詞,刪除此字詞後,再次檢查分析模型在Testing Dataset上的表現,直到分析成功率有顯著的下降
引入所需的Library
import pickle
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
處理字詞
如上一章 Email Preprocess 方式將資料分為Training, Testing Dataset,再經過Tfidf轉換
原先選取當作Training Dataset的Email數量有15820封,作為判斷依據的Word Feature有38260種,為了讓 Decision Tree Overfitting,需要讓Training樣本數量遠小於Word Feature數量,因此以下只選取150封Email當作Training Dataset
### a classic way to overfit is to use a small number
### of data points and a large number of features;
### train on only 150 events to put ourselves in this regime
features_train = features_train[:150].toarray()
labels_train = labels_train[:150]
Decision Tree Classifier
使用sklearn的Decision Tree Classifier,以150封Email作Training Dataset訓練模型,並使用此模型分析Testing Dataset的Email屬於Sara還是Chris
clf = DecisionTreeClassifier()
clf.fit(features_train, labels_train)
pred = clf.predict(features_test)
分類成功率和字詞重要性
分類成功率(Accuracy Score) = 分類成功的Email數量 / Email的總數量
字詞重要性 : Decision Tree Classifier當中,一個字詞作為分類Email的依據,與其他字詞相比其重要的程度,在sklearn裡採用Gini Importance來計算一個字詞在Decision Tree Classifier中的重要性
Gini Importance:
:其值越大,表示分類出的樣本越純粹,例如:若依據某一個字詞分類出的Email其來自於Sara或Chris的比率越高,表示此字詞在分析模型中具有越強的判斷力
:未利用某一個字詞進行分類的Gini Index
和
:利用某一個字詞分類後的Gini Index
和
:分類後其個數佔全部的比率
:計算在Decision Tree的所有節點中,使用某一個字詞X作為分類依據時,其Gini Index乘以其權重的總和,此值為Gini Importance
### Accuracy score
logger.info('The Accuracy Score of the Decision Tree Classifier: %s', accuracy_score(labels_test, pred))
### The important feature
for index, importance_value in enumerate(clf.feature_importances_):
if importance_value > 0.01:
logger.info('(feature, importance value): %s', (vectorizer.get_feature_names()[index], importance_value))
在應該發生Overfitting的情況下,其分類成功率卻高達98.8%,查看字詞重要性,發現 sshacklensf 高達0.74,且此字詞與署名 shackleton 相似,因此要將此字詞刪除
The Accuracy Score of the Decision Tree Classifier: 0.988054607509
(feature, importance value): ('charg', 0.022922344191732679)
(feature, importance value): ('mtaylornsf', 0.051999762286800991)
(feature, importance value): ('nonprivilegedpst', 0.1069864696049095)
(feature, importance value): ('sshacklensf', 0.74529175671503534)
(feature, importance value): ('tjonesnsf', 0.072799667201521381)
刪除sshacklensf 後, 分類成功率降為97.4%, cgermannsf 的字詞重要性為0.64,且此字與署名 germany 相似,因此予以刪除
The Accuracy Score of the Decision Tree Classifier: 0.974402730375
(feature, importance value): ('62502pst', 0.27852609882659246)
(feature, importance value): ('cgermannsf', 0.64418087472201613)
(feature, importance value): ('reliant', 0.050884575747165983)
(feature, importance value): ('tariff', 0.026408450704225324)
刪除兩個為署名的字詞後,分類成功率降為83.1%
The Accuracy Score of the Decision Tree Classifier: 0.831058020478
因為是署名而刪除的字詞為 [“sara”, “shackleton”, “chris”, “germani”, “sshacklensf”, “cgermannsf”]
SVM
SVM Author ID
1.調整SVM的參數,找出精準度最高的SVM模型
2.找出最能用來判別Email寄件者的文字詞 (word feature)
3.分析此SVM模型的精準度,判別能力(Accuracy Score, Confusion Matrix, Precision Score, Recall Score)
引入所需的library
- email_preprocess.py 和 plot_gallery.py 是自訂函式
- email_preprocess.py : 如上一章Preprocess所述, 用來處理Data的格式
- plot_gallery.py : 使用matplotlib進行繪圖
import numpy as np
import pandas as pd
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer, accuracy_score, confusion_matrix, recall_score, precision_score
from email_preprocess import preprocess
from plot_gallery import plot_accuracy_score, plot_feature_importance
調整SVM的參數
利用sklearn的GridSearchCV,放入不同參數到SVM當中,找出最佳的參數
由於每跑一組參數都要重新建構一次SVM的模型,為了不要讓程式跑太久,因此僅放入1/10的Training Data,約200封Email
param_grid = {'C': C_range,
'gamma': gamma_range,
'kernel': kernel_range}
clf = GridSearchCV(SVC(), param_grid, scoring)
clf.fit(features, labels)
| Parameter | Range |
|---|---|
| C | 1e-2 ~ 1e10 |
| gamma | 1e-9 ~ 1e3 |
| kernel | linear, rbf |
C: 決定如何對待錯誤分類,若C值小則允許大量的錯誤分類,讓分類函數簡單,若C值大則盡可能不允許錯誤分類,讓分類函數複雜
gamma: 決定若一個Sample被分類為1,則離這個Sample多遠的範圍也會被分類為1,小的值為遠,大的值為近
kernel: 將Sample投影到更高維度,讓Sample在高維度下能被線性Hyper Plane分割, rbf為將Sample以常態分佈函數投影到高維度再進行分割,linear則是直接在現維度便進行線性分割
以下為不同參數下的Accuracy Score:
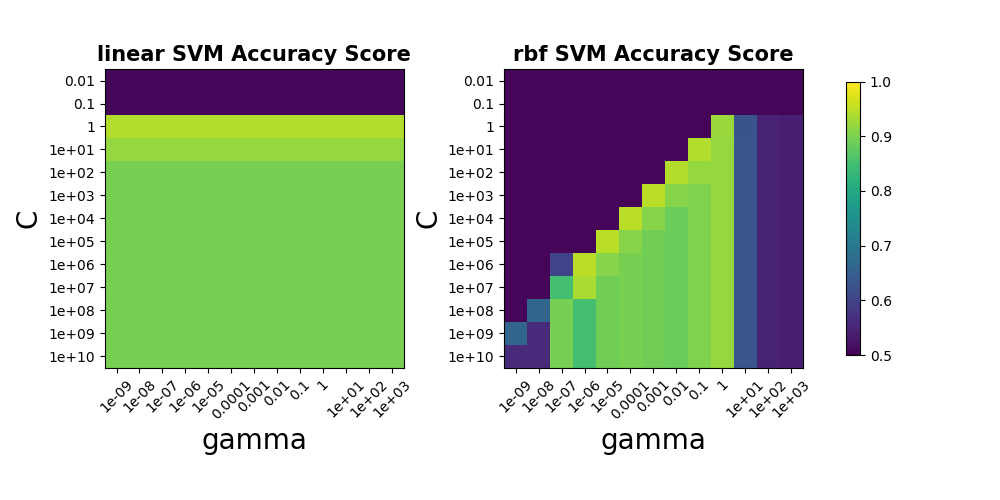
一般SVM使用的是rbf的kernel來建立模型, 然而當Data的feature維度非常大時,便不太需要將Sample投影到高維度,通常可以直接在現維度找到線性的Hyper Plane作分割
由上圖可以發現,由於Word Feature的維度高達1708個,因此使用linear kernel的SVM模型,其精準度並不比rbf kernel來的低
由於從linear kernel的SVM模型中找出最具判別力的字詞較為簡單,因此底下使用linear kernel的SVM作分析
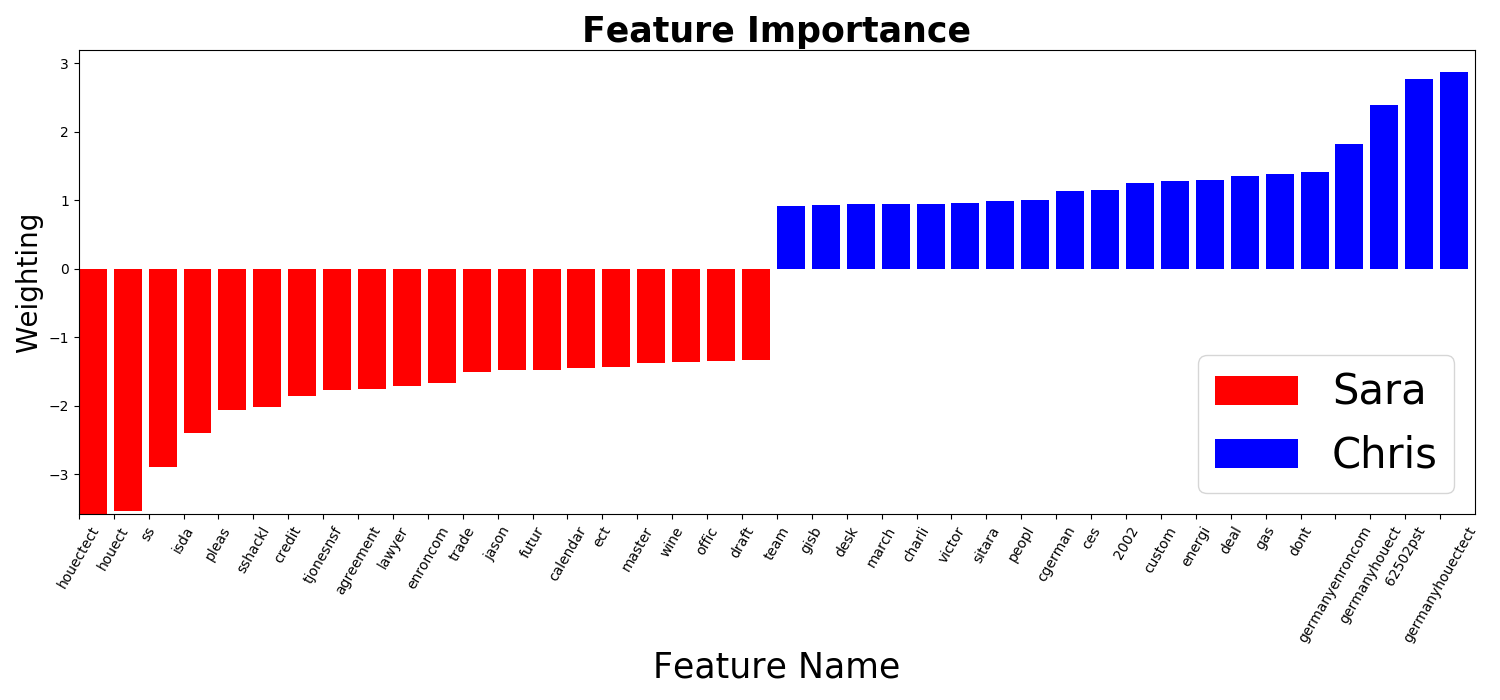
找出最具判別力的字詞
linear kernel SVM的Hyper Plane法向量,可以看成是最能分類Data的方向,若某一個維度(字詞)在此方向上的比重很大,則表示此維度(字詞)分類Data的能力很強;反之,若在此方向上的分量很小,則表示此維度(字詞)分類Data的能力很差,較不重要
因此,讀取linear kernel SVM的Hyper Plane法向量,可以根據比重,知道哪個Email中的字詞最具有判斷能力
下圖為Sara和Chris的Email中判斷力前20的字詞,負的方向為判斷Sara Email的字詞,正的方向為判斷Chris Email的字詞
分析SVM模型的精準度
- Accuracy Score = 97%
- 分類成功的Email數量 / 總共的Email數量
- Accuracy Score很高表示此模型能很好的判別Sara和Chris的Email
| Confusion Matrix | Predicted Sara | Predicted Chris |
|---|---|---|
| True Sara | 7568 (TP) | 312 (FP) |
| True Chris | 146 (FN) | 7795 (TN) |
- Precision Score = 96%
- TP / (TP + FP)
- Precision Score越高,表示Sara的郵件被誤判為Chris的郵件的機率越低
- Recall Score = 98%
- TP / (TP + FN)
- Recall Score越高,表示Chris的郵件被誤判為Sara的郵件的機率越低
由於Precision Score略低於Recall Score,表示Sara的郵件較容易被誤判為Chris的郵件,因此這個模型對Chris郵件的判別力大於Sara郵件
從Confusion Matrix其實也可以很簡單的看出,在Sara和Chris的郵件總數差不多的情況下,Sara的郵件被誤判為Chris的有312封;反之,Chris的郵件被誤判為Sara的146封
Reference
此程式主要的演算法,包括建立分析模型前對Data的處理方式,和使用SVM建立分析模型,參考於線上課程網站Udacity的Nano Degree,Intro to Machine Learning
調整SVM模型不同參數的方法,參考於sklearn的範例頁
找出Email文字中最具判斷力的字詞(Word Feature)的方法,參考於Visualising Top Features in Linear SVM with Scikit Learn and Matplotlib